
Flow Map Learning: A Unified Framework for Fast Generation
Published:
A “flow map” 1 2 3 typically denotes a neural network (or parametric model)
\[f_{\theta}(x_t, t, s) ,\qquad 0\!\le\! s\!\le\! t\!\le\! 1.\]that maps a state at time $t$ directly to a state at a time $s < t$ (often earlier), following the underlying probability-flow ODE or other transport dynamics.
In classical diffusion and flow-matching generative frameworks, the state at time $s$ can be obationed by numerical integration: starting from $x_t$, and perform multiple ODE solver steps to reach $x_s$.
\[x_s = \underbrace{x_t + \int_{t}^{s} v(x_t,t) dt}_{\Phi_{t\to s}(x_t)} ,\qquad 0\!\le\! s\!\le\! t\!\le\! 1.\]where $v$ is a vector field. We use \(\Phi_{t\to s}(x_t)=x_s\) to represent the exact solution operator.
The Flow Map paradigm rethinks this process from a functional perspective. Instead of iteratively integrating a differential equation, it seeks to learn the entire solution operator of that equation, that is to say, a flow map network $f_{\theta}$ aims to approximate this operator family:
\[f_\theta(x_t,t,s)\,\approx\,\Phi_{t\!\to\! s}(x_t) ,\qquad 0\!\le\! s\!\le\! t\!\le\! 1.\]Hence, Flow Map learning transforms diffusion sampling from an integration problem into a function-approximation problem: learn the end-to-end mapping between noise levels, and then generate in one or a few evaluations.
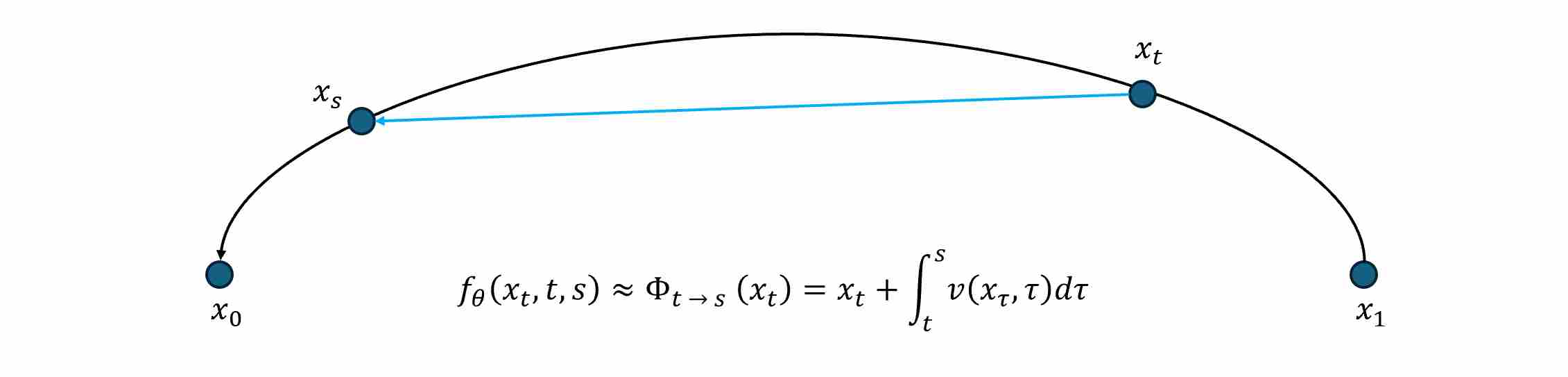
1. Relationship Between Flow Map and Existing Model Families
The Flow Map formulation provides a unified lens through which a wide range of diffusion- and flow-based acceleration methods can be interpreted as special cases or discrete approximations.
1.1 Connection to Consistency Model (CM)
The Consistency Model 4 learns a neural mapping that directly transforms a partially-noised sample $x_t$ into its clean endpoint $x_0$:
\[f_{\theta}^{\mathrm{CM}}(x_t, t) \approx x_0 .\]This can be exactly recovered from Flow Map by setting the target time to the endpoint $s=0$:
\[f_{\theta}(x_t, t, s=0) \; \equiv \; f_{\theta}^{\mathrm{CM}}(x_t, t).\]Hence, CM is a boundary-anchored Flow Map that only learns mappings terminating at the data manifold. While CM focuses solely on consistency between the intermediate prediction $f_{\theta}(x_t,t)$ and the ground-truth $x_0$, Flow Map generalizes this to consistency between any two time instants $(t,s)$, enabling dense self-consistency supervision throughout the temporal domain.
This extension alleviates the “boundary overfitting” problem of CM and allows richer supervision that benefits both few-step and multi-step generation.
1.2 Connection to Flow Matching (FM)
The Flow Matching objective 5 trains a velocity field $v_\theta(x,t)$ that matches the teacher ODE:
\[\frac{d x_t}{d t}=v_\theta(x_t,t)\approx v_\phi(x_t,t).\]This can be viewed as the infinitesimal limit of the Flow Map as the source and target times approach each other:
\[f_{\theta}(x_t,t,s) = x_t+(s-t),v_\theta(x_t,t) +\mathcal{O}\!\big((s-t)^2\big), \qquad s\to t.\]Thus,
\[\boxed{\,\lim_{s\to t}\frac{f_{\theta}(x_t,t,s)-x_t}{s-t} =v_\theta(x_t,t)\,}\]revealing that FM emerges as the differential limit of Flow Map. Conceptually, FM learns the infinitesimal generator of the Flow Map, whereas Flow Map learns the finite-time transport operator itself.
Consequently, Flow Map can be interpreted as an integrated version of FM, capable of performing large temporal jumps without solving an ODE numerically.
1.3 Connection to MeanFlow
The MeanFlow formulation 6 parameterizes the flow mapping linearly with respect to the time interval:
\[\boxed{\,f_{\theta}(x_t,t,s) = x_t+(s-t)\,u_{\theta}(x_t,t,s)\,}\]Here (u_\theta) predicts the average velocity between $t$ and $s$:
\[u_{\theta}(x_t,t,s) \approx \frac{1}{s-t}\!\int_{t}^{s} v_\phi(x_\tau,\tau)\,d\tau.\]This is precisely a re-parameterization of the Flow Map itself—MeanFlow enforces linear interpolation along the temporal interval, effectively constraining $f_{\theta}$ to obey a first-order Euler discretization.
Hence, Flow Map and MeanFlow are functionally equivalent; the only difference lies in parameterization: Flow Map directly learns the endpoint mapping $x_t\mapsto x_s$, whereas MeanFlow learns the average velocity that integrates to the same endpoint.
From a numerical perspective, Flow Map corresponds to solving the ODE with one explicit Euler step whose increment is predicted by $u_\theta$.
1.4 Connection to Consistency Trajectory Model (CTM)
The Consistency Trajectory Model (CTM) 7 can be viewed as the discrete-time instantiation of the Flow Map principle 1. CTM enforces discrete trajectory consistency:
\[f_\theta\!\big(f_\theta(x_{t_2},t_2,t_1),t_1,t_0\big) \approx f_\theta(x_{t_2},t_2,t_0),\]where $t_2>t_1>t_0$. This condition is a discrete approximation of the composition consistency that Flow Map satisfies exactly in the continuous limit:
\[f_\theta\big(f_\theta(x_u,u,t),t,s\big) = f_\theta(x_u,u,s).\]Therefore, CTM can be interpreted as a time-discretized Flow Map trained on finite intervals, ensuring that two short-step predictions compose to the same endpoint as a single long-step prediction.
2. Flow Map Training: Objective and Methods
Let a pretrained teacher vector field $v_\phi(x,t)$ define the continuous probability-flow ODE
\[\frac{d x}{d t}=v_\phi(x,t), \qquad x_s=\Phi_{t\to s}(x_t).\]The goal of the Flow Map model is to train a neural operator
\[\boxed{f_\theta(x_t,t,s)\approx\Phi_{t\to s}(x_t)}\]that can jump from any noise level $t$ to any target level $s$ in one step. Formally, the objective minimizes the deviation between the student flow map $f_\theta$ and the teacher flow solution:
\[\boxed{ \mathcal{L}(\theta) =\mathbb{E}_{x_t,t,s}\!\Big[\, d(\,f_\theta(x_t,t,s), \Phi_{t\to s}(x_t))\,\Big]. }\]Since the true map $\Phi_{t\to s}$ is unavailable in closed form, we approximate it using the teacher vector field and construct distillation losses that align the local behavior of $f_\theta$ with the teacher ODE.
Two complementary formulations arise, corresponding to the Eulerian and Lagrangian viewpoints of fluid dynamics.
2.1 Eulerian Map Distillation (EMD)
EMD fixes the target time $s$ and requires that the prediction at this endpoint be invariant when the starting point $(x_t,t)$ moves infinitesimally along the teacher trajectory. It enforces temporal consistency of the flow map at a fixed destination.
2.1.1 Discrete Form
For a small step:
\[t'\!=\!t+\varepsilon(s-t)\]and
\[x_{t'} = x_t + \varepsilon(s-t),v_\phi(x_t,t)\]the Eulerian consistency loss is
\[\mathcal{L}_{\text{EMD}} = \mathbb{E}_{t,s}\! \left[w(t,s)\, \|\,f_\theta(x_t,t,s) - f_{\theta^-}(x_{t'},t',s)\|_2^2\right]\]where $f_{\theta^-}$ is a stop-gradient copy (no back-prop through the reference branch). This simple MSE form avoids Jacobian–vector-product instabilities and scales well to high-dimensional images.
2.2 Lagrangian Map Distillation (LMD)
LMD fixes the starting point $(x_t,t)$ and enforces that, when the endpoint $s$ changes slightly, the flow-map prediction evolves consistently with the teacher’s instantaneous velocity. It aligns the terminal direction of the student with the teacher vector field—mirroring the Lagrangian, “follow-the-particle” viewpoint.
2.2.1 Discrete Form
For a nearby endpoint:
\[s' = s+\varepsilon(t-s)\]let \(y' = f_{\theta^-}(x_t,t,s')\) and move it through the teacher ODE one Euler step:
\[\widehat{y} = y' + \varepsilon(t-s)\,v_\phi(y',s').\]Then the loss is
\[\mathcal{L}_{\text{LMD}} =\mathbb{E}_{t,s}\! \left[ w(t,s)\, \|\,f_\theta(x_t,t,s) - \widehat{y}\|_2^2 \right]\]3. References
Sabour A, Fidler S, Kreis K. Align Your Flow: Scaling Continuous-Time Flow Map Distillation[J]. arXiv preprint arXiv:2506.14603, 2025. ↩ ↩2
Boffi N M, Albergo M S, Vanden-Eijnden E. Flow map matching with stochastic interpolants: A mathematical framework for consistency models[J]. Transactions on Machine Learning Research, 2025. ↩
Hu Z, Lai C H, Mitsufuji Y, et al. CMT: Mid-Training for Efficient Learning of Consistency, Mean Flow, and Flow Map Models[J]. arXiv preprint arXiv:2509.24526, 2025. ↩
Song Y, Dhariwal P, Chen M, et al. Consistency models[J]. 2023. ↩
Lipman Y, Chen R T Q, Ben-Hamu H, et al. Flow matching for generative modeling[J]. arXiv preprint arXiv:2210.02747, 2022. ↩
Geng Z, Deng M, Bai X, et al. Mean flows for one-step generative modeling[J]. arXiv preprint arXiv:2505.13447, 2025. ↩
Kim D, Lai C H, Liao W H, et al. Consistency trajectory models: Learning probability flow ode trajectory of diffusion[J]. arXiv preprint arXiv:2310.02279, 2023. ↩