
Fast Generation with Flow Matching
📅 Published: | 🔄 Updated:
📘 TABLE OF CONTENTS
- 1. Introduction: FM Faster Than Diffusion-Based PF-ODEs
- 2. RF Bottleneck: Straight but Not Instantaneous
- 3. Reflow: iteratively training makes the path straighter
- 4. InstaFlow: Text-Conditioned Rectified Flow with One-Step Distillation
- 5. Shortcut Model: Few-Step Generation via Step-Conditioned
- 6. MeanFlow: Learning Mean Velocity Fields for One-Step Generation
- 7. Inductive Moment Matching
- 8. References
While Flow Matching (FM) offers a geometrically elegant alternative to diffusion models by learning continuous probability flows rather than stochastic denoising trajectories, its inference remains computationally expensive. Despite the apparent “straightness” of the learned flow fields, generation still requires solving an ordinary differential equation (ODE) over many discrete steps. This blog investigates why Flow Matching is not inherently fast, tracing the inefficiencies that persist even in rectified or linearized trajectories. We then present and analyze recent advances designed to accelerate FM sampling—Rectified Flow, InstaFlow, Shortcut, and MeanFlow—which progressively move from geometrical straightening to functional reformulation and finally to one-step direct mappings. By contrasting their motivations, formulations, and numerical behaviors, we reveal a unifying view of flow acceleration as a shift from learning instantaneous velocity fields to learning integral or averaged mappings that approximate the entire transport process in minimal function evaluations. The discussion concludes by outlining open challenges toward achieving true one-step generative flows that bridge physical interpretability, numerical stability, and computational efficiency.
1. Introduction: FM Faster Than Diffusion-Based PF-ODEs
Flow Matching (FM) 1 was originally proposed as a deterministic and conceptually elegant alternative to diffusion models. Instead of modeling noisy Markov chains or stochastic denoising processes, FM directly learns a continuous velocity field $ v_\theta(x, t)$ that defines a probability flow ODE. This ODE transports samples smoothly from a simple prior distribution (e.g., Gaussian noise) to the target data distribution. In principle, this framework eliminates stochasticity, reduces sampling variance, and offers a clean geometric interpretation of generation as a continuous mass transport problem.
Although both DM and FM can be expressed as deterministic ODEs during inference, they differ fundamentally in how these ODEs are defined and what they are trained to approximate. The key lies not in the mathematical form of the equations, but in the origin of the training objective and the geometry of the learned transport paths.
1.1 Diffusion PF-ODEs: A By-Product of a Stochastic Process
In diffusion models, the forward dynamics follow a stochastic differential equation (SDE):
\[dx=f(t,x)\,dt+g(t)\,dw_t\]where $w_t$ denotes Brownian noise. The model is trained to predict auxiliary targets—noise $\epsilon_\theta$, score $\nabla_x\log p_t(x)$, or the denoised sample $x_{0,\theta}$—that are defined with respect to this noisy diffusion process. During inference, one can reformulate the reverse SDE into a deterministic probability-flow ODE (PF-ODE):
\[\frac{dx}{dt}=f(t,x)-\tfrac{1}{2}g(t)^2 s_\theta(x,t).\]Although this PF-ODE yields the same marginal distribution as the reverse SDE, it is not the quantity being optimized during training; it merely arises as an analytical consequence of the stochastic objective. Therefore, the learned flow inherits the geometric irregularities of the noisy trajectories. The resulting velocity field remains highly curved in high-dimensional space, forcing numerical solvers to use small step sizes to maintain accuracy and stability.
1.2 Flow Matching: Learning the ODE Itself
Flow Matching inverts this paradigm. It defines the deterministic ODE as the primary learning target rather than as a by-product. Given a source sample $x_0$ and a target data $x_1$, FM introduces an explicit interpolation
\[x_t = \alpha_t x_0 + \beta_t x_1,\]and supervises the network to approximate the true conditional velocity
\[v_t = \frac{d}{dt}x_t = \dot\alpha_t x_0 + \dot\beta_t x_1.\]The model minimizes
\[\mathcal{L}_{\text{FM}}= \mathbb{E}_{x_0,\epsilon,t}\left[\|v_\theta(x_t,t)-v_t\|^2\right],\]which directly teaches the network how to move data points through time. Unlike diffusion models—where the PF-ODE is recovered after training—FM optimizes the ODE itself. As a result, the learned field $v_\theta(x,t)$ tends to be geometrically straight and globally smooth, leading to deterministic transport with lower curvature and improved numerical stability.
In geometric terms, diffusion’s PF-ODE performs a passive simplification of stochastic paths, whereas Flow Matching performs an active planning of deterministic, near-geodesic trajectories. This distinction explains why FM usually achieves high-fidelity synthesis with only 10–20 NFEs, compared to the 50–100 NFEs typically required by diffusion-based PF-ODEs.
2. RF Bottleneck: Straight but Not Instantaneous
We had discussed Rectified Flow, a specifical case of FM, who defines the probability path as a straight line from the start point ($x_0 \sim p_{\text{init}}$) to the end point ($x_1 \sim p_{\text{data}}$) through linear interpolation. Therefore, in theory, RF can achieve one-step generation.
\[x_t = (1-t)x_0 + tx_1\, \Longrightarrow\, \frac{dx_t}{dt} = x_1-x_0\]However, in practice, the trajectory of the ODE remains a curve. The core reason is thar the learned vector field is the average instantaneous velocity at each spatial point $x_t=x$ and time $t$:
\[v^{\star}(x, t) = \mathbb{E}\big[\partial_t x_t \,\big|\, x_t = x\big] = \mathbb{E}\big[x_1 - x_0 \,\big|\, x_t = x\big].\]Therefore, what the model learns is not the deterministic velocity of a specific straight-line path, but the conditional expectation of velocities across all possible paths at that point. The following figures shows the straight-line paths between different sample pairs.
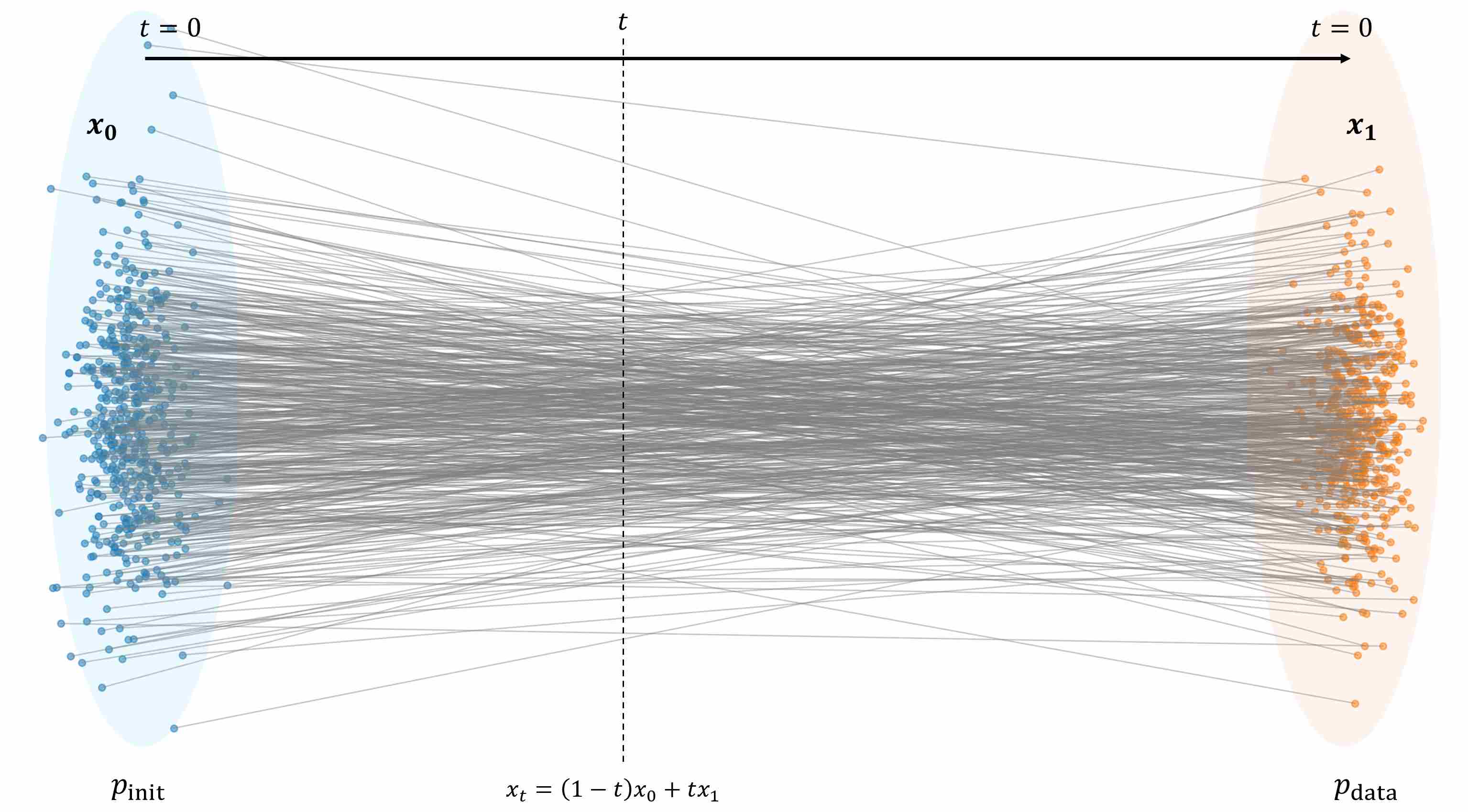
However, given this sample dataset, the obtained ODE trajectory is curved, as shown in the following figure.
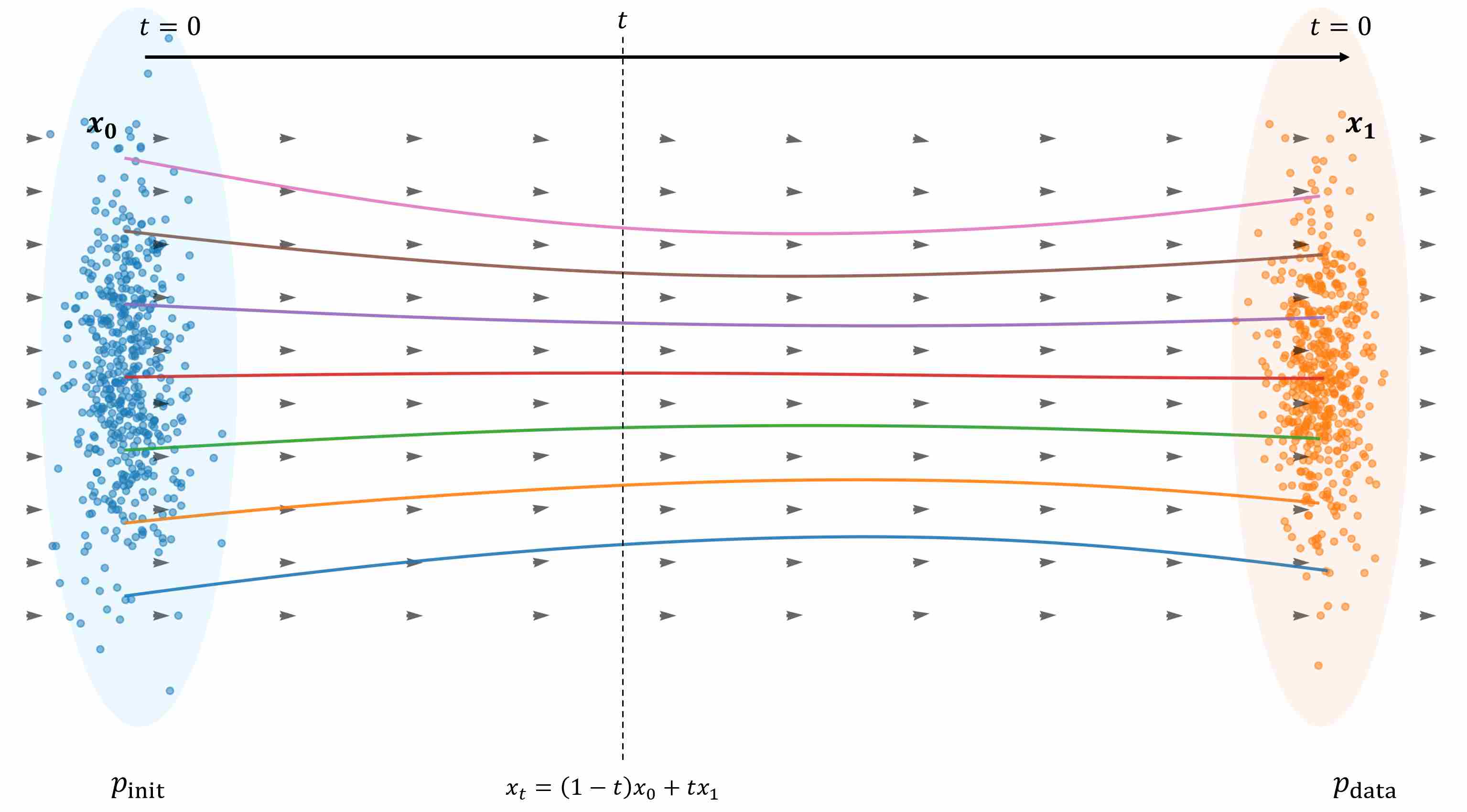
2.1 Mathematical View
The Key Idea is that local averaging of velocities causes curvature: Many different pairs $(x_0, x_1)$ may pass near the same spatial location $x_t = x$, each with a different direction $x_1 - x_0$, when we take the average direction of all those local velocities, the resulting mean velocity vector depends on where $x$ is located.
Hence, the mean velocity field $v^\star(x, t)$ is spatially non-uniform — it bends, twists, and changes direction smoothly across space.
From a mathematical perspective, the mean velocity at location $x$ is:
\[v^\star(x, t) = \int (x_1 - x_0) \, p(x_0, x_1 \mid x_t = x) \, dx_0 \, dx_1.\]where $p(x_0, x_1 \mid x_t = x)$ is conditional distribution of start ($x_0$) and end points ($x_1$) given the intermediate position ($x_t$), which is usually not a constant, because for different values of $x_t=x$, there are different pairs \((x_0, x_1)\) passing through, which typically forms a very complex distribution. Thus, $v^\star(x, t)$ is not constant in space, and integrating it yields curved streamlines.
2.2 Motivation to ReFlow
The bottleneck of Rectified Flow is not the linear interpolation itself, but the random coupling: multiple endpoint pairs can pass through the same $(x, t)$, forcing the optimal vector field to become a conditional average and thus spatially varying.
In next section, we discuss ReFlow, ReFlow addresses this by inducing a progressively more deterministic coupling from the learned flow, collapsing the conditional ambiguity and making the resulting streamlines straighter.
3. Reflow: iteratively training makes the path straighter
As we had mentioned above, the hidden curvature problem makes sampling procedure still relies on multi-step numerical integration. This discrepancy motivates ReFlow: an iterative method to straighten the learned trajectories and accelerate sampling.
ReFlow is an iterative self-distillation procedure applied on top of Rectified Flow. In practice, the first rectified flow $v_\theta^{(1)}$ learned from random couplings \((x_0, x_1) \sim p_0 \times p_1\) may not achieve perfect linearity. Thus, the authors propose ReFlow, an iterative self-distillation procedure:
Step 1: Use the current flow $v_\theta^{(k)}$ to generate new data pairs:
\[x_1' = x_0' + \int_{0}^{1} v_\theta^{(k)}(t, x_t) dt, \quad (x_0' \sim p_0).\]Step 2: Treat $(x_0’, x_1’)$ as new couplings and re-train:
\[v_\theta^{(k+1)} = \arg\min_{\theta} \int_0^1 \mathbb{E}\Bigg[\|(x_1' - x_0') - v_\theta^{(k)}((1-t)x_0' + t x_1', t)\|^2\Bigg] dt. \tag{6}\]
Repeat the above steps, each iteration yields straighter trajectories and smaller transport cost.This process can be viewed as a geometry-level self-distillation: each generation acts as a teacher defining a more coherent flow geometry, while the student learns to approximate it using newly induced couplings.
3.1 Improving the Training: One Reflow is Sufficient
In practical settings, research 2 indicated that the trajectory curvature of the optimal 2-rectified flow is actually close to zero. the linear interpolation paths of pairs generated by 1-Rectified Flow almost never intersect.
Suppose there are two points, $x_1\sim p_{\text{init}}$ and $x_2\sim p_{\text{init}}$, both sampled from the initial distribution, and the vector field obtained by 1-rectified flow is $v_{\theta}^1$. Then, following this vector field $v_{\theta}^1$, the sampling results for these two points are:
\[\begin{align} z_1=x_1+\int_{0}^{1} v_{\theta}^1(t, x_t) dt \\[10pt] z_2=x_2+\int_{0}^{1} v_{\theta}^1(t, x_t) dt \end{align}\]These two trajectories (\(x_1 \to z_1\) and \(x_2 \to z_2\)) almost never intersect. Since if two linear interpolation trajectories intersect, there exist \(t^*\in(0,1)\) and satisfy
\[\begin{aligned} & (1-t^*)x_1 + t^* z_1 \;=\; (1-t^*)x_2 + t^* z_2 \\[10pt] \Longleftrightarrow\quad & (1-t^*)(x_1-x_2) + t^*(z_1-z_2)=0 \\[10pt] \Longleftrightarrow\quad & z_2-z_1 = \frac{1-t^*}{t^*}(x_2-x_1). \end{aligned}\]that implys that $z_2-z_1$ is parallel to $x_2-x_1$, which is almost impossible under high-dimension space.
This pivotal observation shifts the focus from adding more Reflow stages to perfecting the training of the 2-Rectified Flow itself. We can explain this in more detail,
1-Rectified Flow Training: at the beginning of Flow Matching training, we draw pairs
\[(x_0, x_1) \sim \pi_0(x_0, x_1) = p_{\text{init}}(x_0) \times p_{\text{data}}(x_1),\]However, this coupling $\pi_0$ is random and unstructured — there is no consistent mapping between points in $p_0$ and $p_1$. Different sample pairs $(x_0, x_1)$ may cross in space, the optimal flow field
\[v^\star(x,t) = \mathbb{E}[x_1 - x_0 \mid x_t = x]\]represents only the average direction across those mixed trajectories, hence the learned field $v_1$ is curved, because its direction varies spatially.
2-Rectified Flow Training: When we use $v_1$ to generate new samples:
\[x_1^{(1)} = \Phi_{v_1}(x_0),\]where $\Phi$ is an ODE Solver, we create a new coupling \(\pi_1(x_0^{(1)}, x_1^{(1)})\) with two crucial properties:
Deterministic mapping. Each $x_0^{(1)}$ maps to a unique endpoint $x_1^{(1)}$. Hence, $\pi_1$ is no longer a random or mixed coupling — it is now deterministic.
Directional consistency. Along the ODE, the instantaneous velocity is fixed by the field $v_1(x_t, t)$, so all trajectories passing through the same point $x_t$ share the same direction. This eliminates local uncertainty:
\[\mathrm{Var}(x_1^{(1)} - x_0^{(1)} \mid x_t) \approx 0.\]
In other words, while $v_1$ may still appear curved in a global sense, the flow it induces is locally coherent — all particles follow the same vector field, removing the randomness in direction that caused curvature in the first place.
Unlike the 1-Rectified Flow training, the 2-Rectified Flow can be maximized the effectiveness by the following techniques.
U-Shaped Timestep Distribution: The training difficulty for 2-Rectified Flow is not uniform across time t. The tasks at the endpoints—prediction at $t=0$ (from noise to image) and inversion at $t=1$ (from image back to noise)—are far more challenging than the interpolation task in the middle.
Incorporating Real Data: Training 2-rectified flow does not require real data (i.e., it can be data-free), but we can use real data if it is available. mixing endpoints strategy: with probability $1-p$ take a real endpoint, with probability $p$ take a synthetic endpoint.
Advanced Loss Function (LPIPS-Huber Loss): The original L2 loss is suboptimal for image generation as it often leads to blurry results and is sensitive to outliers. The new approach leverages the knowledge that the optimal flow is straight, allowing for more flexible loss functions.
4. InstaFlow: Text-Conditioned Rectified Flow with One-Step Distillation
In previous articles (Accelerating Diffusion Sampling), we introduced how to use distillation to accelerate the sampling of diffusion models. However, as we discussed in Sec. 1.1, diffusion models are based on the path strategy of SDEs, while PF-ODE being merely a by-product, which leads to suboptimal results in distillation. InstaFlow 3 extends this line of work by combining Rectified Flow with ReFlow and a final one-step distillation, transforming a large diffusion model (e.g., Stable Diffusion) into a high-quality, single-step flow generator.
4.1 Overview: From Stable Diffusion to One-Step Flow
InstaFlow can be viewed as a two-stage rectification and distillation pipeline:
Step 1: Teacher Initialization. Start from a pretrained diffusion model (e.g., Stable Diffusion) and interpret its deterministic sampling process as a probability flow ODE:
\[\frac{dx}{dt} = v_{\text{SD}}(x, t \mid c)\]where $c$ is the text condition. By integrating this ODE for 20–50 steps, the model generates pairs $(x_0, x_1)$ — noise to image mappings under given text conditions.
Step 2: ReFlow Rectification. Apply Rectified Flow training on the collected dataset $(x_0, x_1, c)$, learning a smoother and more linear velocity field $v_{\theta}(x,t\mid c)$. This is the text-conditioned ReFlow stage, which regularizes the geometry of the generative flow under each prompt $c$.
Step 3: Distillation to One-Step Flow. A student network $\tilde{v}_\phi(x_0\mid c)$ is trained to approximate the final displacement:
\[x_1 \approx x_0 + \tilde{v}_\phi(x_0 \mid c)\]where
\[x_1 = x_0 + \int_0^1 v_{\theta}(x_t,t\mid c) dt\]using a perceptual distance loss (LPIPS). This collapses the full ODE integration into a single Euler step, enabling instantaneous generation.
4.2 Text-Conditioned ReFlow
ReFlow training described aboved of step 2 is conditioned ReFlow. Unlike the original ReFlow which is unconditional, InstaFlow introduces text-conditioned Rectified Flow by conditioning $v_{\theta}(x,t)$ on textual embeddings $c$ through cross-attention. The training objective becomes:
\[\mathcal{L}_{\text{ReFlow-Cond}} = \mathbb{E}_{x_0,c}\left[\int_0^1 \|(x_1(c)-x_0) - v_{\theta}(x_t, t \mid c)\|^2 dt\right],\]where $x_1(c)$ is generated via the teacher Stable Diffusion model under the same text condition $c$. Each ReFlow iteration improves the local straightness of conditional trajectories without altering their marginal image distribution.
This step is essential because conditional generation introduces multiple sub-manifolds (different prompts induce different flow geometries). Text-conditioned ReFlow ensures each submanifold’s flow is straightened individually, preserving semantic alignment across conditions.
4.3 One-Step Distillation
After obtaining a 2-Rectified Flow teacher, InstaFlow performs a final distillation to a one-step generator. The student network learns a displacement field that directly maps noise to image:
\[\tilde{v}_\phi = \arg\min_\phi \mathbb{E}_{x_0,c}[ \text{dist}(\ \underbrace{\text{ODE-Solver}(\Phi_{0 \to 1}^{v_\theta}(x_0\mid c))}_{\text{ReFlow Teacher}}\,,\, \underbrace{x_0 + \tilde{v}_\phi(x_0\mid c)}_{\text{One step InstaFlow}}\ ) ],\]where $\text{dist}(\cdot, \cdot)$ denotes a perceptual similarity loss (e.g., LPIPS + Huber). The resulting model, InstaFlow, generates a 512×512 image in ~0.09 seconds with quality comparable to 20–50 step diffusion sampling.
4.4 Practical Insights and Limitations
In essence, InstaFlow extends ReFlow into the conditional domain and compresses the entire ODE integration into a single learned displacement. It demonstrates that rectifying and distilling a diffusion teacher can yield true one-step generation without sacrificing image quality.
Text Coverage Issue: Since ReFlow training relies on data generated by Stable Diffusion, text conditions $c$ that are rarely sampled yield few training pairs $(x_0, x_1, c)$. As a result, InstaFlow inherits the coverage limitations of its teacher: performance degrades for rare or unseen prompts.
Improvement Strategies: Expanding the prompt dataset, applying prompt resampling (e.g., CLIP-based diversity sampling), or self-distillation with prompt augmentation can mitigate this bias.
Relation to Diffusion Distillation: The same limitation exists in all conditional distillation frameworks — missing conditions lead to poor generalization. InstaFlow emphasizes path rectification before distillation, which reduces geometric variance and improves knowledge transfer.
5. Shortcut Model: Few-Step Generation via Step-Conditioned
In Section 3, ReFlow progressively straightened the flow field to reduce curvature; in Section 4, InstaFlow distilled a rectified teacher into a one-step student to achieve direct generation.
However, both still operate under a common assumption: the model is trained to predict an instantaneous velocity $v(x,t)$, but at inference time, when we attempt to generate samples using only a few or even a single step, we are effectively executing a finite-time jump. This mismatch between infinitesimal training and finite inference leads to systematic biases and degraded quality. The Shortcut model aims to close this gap by explicitly conditioning on the step size and learning the finite-interval displacement direction. In other words, it learns not how to move infinitesimally, but how to jump across a time interval directly.
5.1 Formulation and Motivation
the Shortcut model introduces an explicit conditioning variable — the step size $d\in(0,1]$ — and learns a field $s_\theta(x_t,t,d)$ that predicts the average direction over the time interval $[t, t+d]$:
\[x_{t+d} = x_t + s_\theta(x_t,t,d)\,d.\]When $d\to 0$, this recovers the original FM setting since the average velocity over an infinitesimal interval equals the instantaneous velocity:
\[s_\theta(x,t,0) = \lim\limits_{d \to 0} \frac{x_{t+d}-x_t}{d} = v(x,t)\]But for larger $d > 0$, the network learns to compensate for curvature and multimodality by directly regressing the finite-time displacement. In this sense, the Shortcut field acts as a generalized velocity, simultaneously encompassing both small-step and large-step behaviors. The model learns not only local tangent information but also how to interpolate or “shortcut” across a segment of the trajectory.
The key insights is that: If the Shortcut field truly represents a physically consistent finite-step motion, then composing two half-steps of size $d$ should yield the same displacement as a single large step of size $2d$. To encode this additivity property, the following self-consistency identity is imposed:
\[s(x_t,t,2d) = \frac{1}{2}\, s(x_t,t,d) + \frac{1}{2}\, s(x'_{t+d},t+d,d),\]where $x’_{t+d}=x_t + s(x_t,t,d)d$ is the predicted midpoint. This elegant identity can be interpreted as a discrete form of trajectory composition: the large-step direction equals the average of two consecutive small-step directions. Geometrically, this encourages the learned field to be smooth and consistent across scales of time, ensuring that predictions at different step sizes form a coherent hierarchy.
Unlike methods such as ReFlow or InstaFlow, which require generating teacher trajectories, this condition is imposed directly on the model’s own outputs, allowing end-to-end training without external supervision.
5.2 Training and Inference: Learning to Jump Consistently
The Shortcut training objective integrates two complementary components:
Small-step anchoring (FM base): For $d=0$, the model must recover the classical FM velocity:
\[\mathcal L_{\text{FM}} = \mathbb E_{x0, x1, t} \| s_\theta(x_t,t,0) - (x_1 - x_0) \|^2.\]Self-consistency across scales: For $d>0$, enforce the additive consistency constraint:
\[\mathcal L_{\text{SC}} = \mathbb E_{d, t} \| s_\theta(x_t,t,2d) - s_{\text{tgt}} \|^2\]where
\[s_{\text{tgt}} = \frac{1}{2}s_\theta(x_t,t,d) + \frac{1}{2}s_\theta(x'_{t+d},t+d,d).\]
In practice, we use stop-gradient or an EMA copy of the network to compute $s_{\text{tgt}}$ for stable bootstrapping.
The overall loss is:
\[\mathcal L(\theta) = \mathcal L_{\text{FM}} + \mathcal L_{\text{SC}}.\]At inference, the same model can be used for any number of steps $M$. Set $d=1/M$, and evolve:
\[x \leftarrow x + s_\theta(x,t,d)\,d, \quad t\leftarrow t+d.\]This single model thus supports:
- One-step generation (M=1): Directly jumps from noise to data.
- Few-step generation (M∈{2,4,8}): Allows intermediate refinements.
- Multi-step generation (M≈64–128): Recovers high-fidelity sampling equivalent to standard FM.
Because $s_\theta(x,t,d)$ explicitly depends on $d$, the model automatically adjusts its prediction to different integration granularities. This yields robust behavior across sampling budgets without any retraining or distillation.
6. MeanFlow: Learning Mean Velocity Fields for One-Step Generation
Although Flow Matching (FM) and Rectified Flow (RF) have provided a unified ODE view of generative modeling, both still rely on instantaneous velocity fields $v(x_t, t)$ and therefore require numerical integration during sampling. When the integration step is coarse (e.g., 1–4 steps), numerical error accumulates rapidly because the marginal flow trajectories are not perfectly straight even if the conditional flow is linear. This limitation makes true one-step generation (1-NFE) difficult: the model is trained to predict a continuous-time velocity field but is asked to execute a large discrete jump during inference.
To overcome this structural mismatch, MeanFlow 4 proposes to replace the instantaneous velocity by its temporal average, thus directly learning a quantity that corresponds to a finite displacement rather than an infinitesimal one. By learning the mean velocity field
\[u(x_t, t, t_{\text{end}}) = \frac{1}{t_{\text{end}}-t} \int_t^{t_{\text{end}}} v(x_\tau, \tau)\, d\tau,\]The relation between instantaneous velocity and mean velocity is shown as follows.
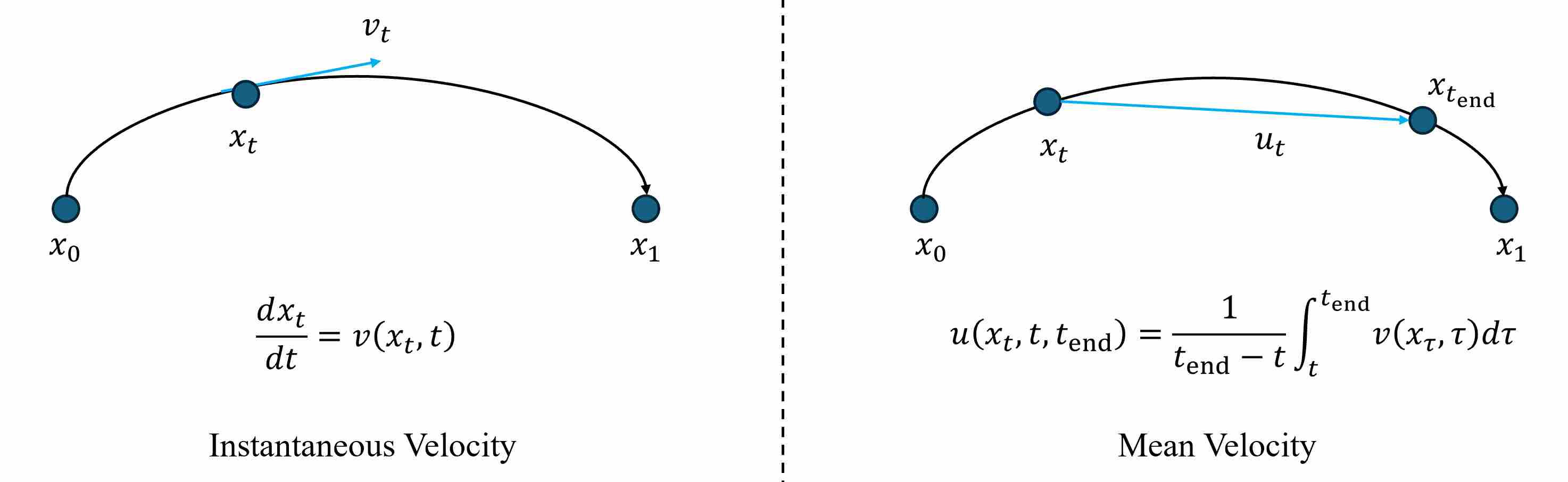
MeanFlow explicitly models the average motion between two time instants $t$ and $t_{\text{end}}$.
\[x_{t_{\text{end}}} = x_t + (t_{\text{end}}-t)\,u(x_t, t, t_{\text{end}})\]This design removes the need for numerical ODE integration: a single evaluation of (u) gives a displacement estimate capable of jumping directly from noise $(t{=}0)$ to data $(t_{\text{end}}{=}1)$.
\[x_1 = x_0 + u(x_0, t=0, t_{\text{end}}=1)\]6.1 MeanFlow Identity
Differentiating the definition of $u$ with respect to $t$ gives
\[\frac{d}{dt}\!\left[(t_{\text{end}}-t)u(x_t, t, t_{\text{end}})\right] = \frac{d}{dt} \int_t^{t_{\text{end}}} v(x_\tau, \tau)\, d\tau = -v(x_t, t).\]Applying the product rule to the left side, leading to the MeanFlow Identity
\[\boxed{\, u(x_t, t, t_{\text{end}}) = v(x_t, t) + (t_{\text{end}}-t)\,\frac{d}{dt}u(x_t, t, t_{\text{end}}) \,}\label{eq:meanflow1}\]This equation forms the theoretical foundation of MeanFlow: it expresses the instantaneous velocity in terms of the mean velocity and its total derivative. Conversely, the identity uniquely determines $u$ given $v$ and vice versa.
The total derivative $\tfrac{d}{dt}u(x_t, t, t_{\text{end}})$ contains both explicit and implicit time dependence, using chain rule gives
\[\begin{align} \frac{d}{dt}u(x_t, t, t_{\text{end}}) & = \underbrace{\frac{dx_t}{dt}}_{v(x_t, t)} \partial_{x_t} u + \underbrace{\frac{dt}{dt}}_{1} \partial_{t} u + \underbrace{\frac{dt_{\text{end}}}{dt}}_{0} \partial_{t_{\text{end}}} u \\[10pt] & = v(x_t, t) \partial_{x_t} u(x_t, t, t_{\text{end}})+ \partial_{t} u(x_t, t, t_{\text{end}}) \\[10pt] & = \underbrace{[\partial_{x_t} u,\,\, \partial_{t} u,\,\, \partial_{t_{\text{end}}} u]}_{\text{Jacobian Matrix}} \cdot [v, 1, 0]^T\label{eq:meanflow2} \end{align}\]This is a Jacobian-vector product (JVP) that can be efficiently computed with modern autodiff frameworks (PyTorch, JAX) without incurring second-order gradient cost, as gradients are detached from the target branch.
6.2 Training Objective
Let $u_\theta(x_t, t, t_{\text{end}})$ denotes the neural network predicting the mean velocity. Substituting Eq. \ref{eq:meanflow2} into Eq. \ref{eq:meanflow1} yields a regression target:
\[u_{\text{target}} = v(x_t, t) + (t_{\text{end}}-t)(v(x_t, t)\partial_{x_t} u + \partial_{t} u)\]When $t_{\text{end}}{=}t$, the second term vanishes and the loss degenerates to Flow Matching, ensuring compatibility. The training loss is a simple mean-squared error:
\[\mathcal L(\theta) = \big\| u_\theta(x_t, t, t_{\text{end}}) - \text{stopgrad}(u_{\text{target}}) \big\|_2^2.\]Sampling is simple, only one forward pass through $u_\theta$ suffices to map pure noise ($x_0=\epsilon$) to data.
\[x_1 = \epsilon + u_\theta(x_0, t{=}0, t_{\text{end}}{=}1)\,\qquad \epsilon \sim \mathcal N(0,I)\]6.3 MeanFlow vs Shortcut: Continuous Theory vs Discrete Realization
MeanFlow and Shortcut address the same pain point—high-quality few/one-step generation—by learning interval information instead of relying solely on instantaneous velocities as in classic Flow Matching (FM) or Rectified Flow (RF). Conceptually:
MeanFlow is a continuous-time formulation: it defines and learns an average velocity field over a time interval, derived from first principles of the probability flow ODE.
Shortcut is a discrete-time realization: it learns a finite-step displacement direction and enforces self-consistency across steps—behaving like a learned, problem-adapted numerical integrator for the same underlying ODE.
With $t_{\text{end}}=t+d$:
\[s(x_t,t,d)\;\approx\;u(x_t,t,t+d)\;=\;\frac{1}{d}\int_{t}^{t+d} v(x_\tau,\tau),d\tau\]Hence, Step size $d$ in Shortcut is equal to interval length $(t_{\text{end}}-t)$ in MeanFlow. One-step sampling
\[\underbrace{x_0 = x_1 - s(x_1,0,1)}_{\text{Shortcut}}\quad\leftrightarrow\quad \underbrace{x_0 = x_1 - u(x_1,0,1)}_{\text{MeanFlow}}.\]6.3.1 Neural Integrator View: Shortcut as a Family of RK-like Schemes
We can also understand the relationship between meanflow and shortcut from the perspective of numerical integration. Specifically, if we regard meanflow as a continuous ODE, then shortcut is a type of discrete solution method for this ODE.
Interpreting $s_\theta$ as a learned local average velocity, Shortcut’s target can be generalized to emulate classic ODE integrators:
Trapezoidal / Midpoint (2nd-order) — current common form
\[s_{\text{tgt}}=\frac{1}{2}\,s_\theta(x_t,t,d)+\frac{1}{2}\,s_\theta(x_{t+d},t+d,d)\]Heun / Improved Euler (2nd-order)
\[s_{\text{tgt}}=\frac{2}{3}\,s_\theta(x_t,t,\tfrac{2}{3}d)+\frac{1}{3}\,s_\theta(x_{t+\tfrac{2}{3}d},t+\tfrac{2}{3}d,\tfrac{1}{3}d)\]General RK-style template
\[s_{\text{tgt}}=\sum_{i=1}^k w_i\,s_\theta\!\big(x_{t+\alpha_i d},\,t+\alpha_i d,\,\beta_i d\big), \quad \sum_i w_i=1,\]where the nodes/weights $(\alpha_i,\beta_i,w_i)$ define accuracy/stability trade-offs.
In summary, MeanFlow provides the continuous target—the interval average (u). Shortcut instantiates a discrete quadrature of that average with learnable evaluations of $s_\theta$ at selected nodes.
7. Inductive Moment Matching
Inductive Moment Matching (IMM) 5 can be viewed as a natural next step after Shortcut and MeanFlow: instead of learning instantaneous velocity (FM/RF), or learning interval information such as a step-conditioned displacement (Shortcut) or a mean velocity (MeanFlow), Inductive Moment Matching (IMM) 5 directly learns a two-time transport operator— a flow map-like predictor that can jump from time $t$ to any later time $s$ (or, in the diffusion convention, from noisier time to cleaner time) in a single network evaluation.
The key conceptual shift is:
- Shortcut / MeanFlow: enforce self-consistency mostly through pointwise regression targets (with stop-gradient/EMA).
- IMM: enforces self-consistency in distribution, by matching moments of two induced distributions via an MMD-style objective.
This “distributional induction” is precisely what makes IMM empirically stable at scale and naturally supports inference-time scaling (1-step → few-step → more steps) using the same trained model.
7.1 Two-Time Operators as Learned Flow Maps
Recall the flow map viewpoint (Check this post for detailed discussion): for an ODE
\[\frac{d x_t}{dt} = v(x_t,t),\]the exact solution between two times is a mapping
\[\Phi_{t\to s}:\; x_t \mapsto x_s, \qquad s<t,\]which satisfies the semigroup property
\[\Phi_{t\to s} = \Phi_{r\to s}\circ \Phi_{t\to r}, \qquad t>r>s.\]flow matching learns $v_\theta$ and approximates $\Phi_{t\to s}$ by numerical integration. IMM instead parameterizes the flow maps directly:
\[x_s \approx f_{\theta}(x_t;\, t,s), \qquad 0\le s<t\le 1,\]so that sampling becomes composition of learned maps rather than integration of a learned vector field.
From the perspective of this blog, IMM is therefore a “flow-map model trained from scratch”: it does not require a teacher solver at training time, and it does not require distillation into a one-step student—its training objective is built to make multi-step composition consistent by design.
7.2 Self-Consistent Interpolants and a Deterministic Parameterization
IMM is formulated on top of a self-consistent interpolant (closely related to stochastic interpolants and DDIM-style deterministic paths). Concretely, one can generate a whole trajectory \(\{x_t\}_{t\in[0,1]}\) from a pair $(x,\epsilon)$ using a schedule $(\alpha_t,\sigma_t)$:
\[x_t = \alpha_t x + \sigma_t \epsilon, \qquad x \sim p_{\text{data}},\;\epsilon\sim \mathcal N(0,I).\]A crucial property is self-consistency: the “same” state at an intermediate time can be obtained consistently from the same endpoint pair (no teacher model required), and composing two transitions equals a direct transition along the same path.
IMM then chooses a deterministic conditional family (a “delta conditional”):
\[p^\theta_{s|t}(x_s\mid x_t)=\delta\big(x_s - f_\theta(x_t;t,s)\big),\]and in practice adopts a DDIM-wrapped parameterization:
\[f_\theta(x_t;t,s) \;:=\; \mathrm{DDIM}\Big(x_t,\; g_\theta(x_t,t,s),\; t,s\Big),\]where $g_\theta(\cdot)$ is the neural prediction (e.g., an estimate of the clean endpoint), and $\mathrm{DDIM}(\cdot)$ is the deterministic “trajectory-consistent” reparameterization that ensures outputs live on the same family of paths.
This deterministic form is important for IMM’s philosophy: the model is not asked to predict an infinitesimal vector (FM), but rather a finite-time operator that can be composed, compared, and constrained across scales.
7.3 Inductive Moment Matching: Distributional Self-Consistency via MMD
IMM enforces a flow-map semigroup principle, but in distribution. Pick three times
\[t > r > s.\]There are two ways to obtain a candidate sample at time $s$:
Direct jump (one operator evaluation): \(y_{s,t} = f_\theta(x_t;\, t,s).\)
Inductive (composed) route: first move along the same underlying interpolant to get $x_r$ (this uses the known interpolant consistency, not a learned solver), then apply the learned operator from $r$ to $s$:
\[y_{s,r} = f^-_\theta(x_r;\, r,s),\]where $f^-_\theta$ denotes a stop-gradient / EMA copy used as a bootstrap target (exactly in the spirit of Shortcut’s self-consistency training).
IMM’s core idea is to require that the induced distributions of $y_{s,t}$ and $y_{s,r}$ match, i.e.,
\[\mathcal L_{\text{IMM}}:\quad \mathcal L\big(\, \mathcal L(y_{s,t}),\;\mathcal L(y_{s,r})\,\big)\;\text{is small}.\]Instead of KL (which is hard to estimate without densities), IMM uses Maximum Mean Discrepancy (MMD) with a kernel $k(\cdot,\cdot)$. A convenient unbiased two-sample form used in IMM can be written as:
\[\small \widehat{\mathcal L}_{\text{IMM}}(\theta) = \mathbb E_{s,t}\Big[ w(s,t)\big( k(y_{s,t},y'_{s,t}) + k(y_{s,r},y'_{s,r}) - k(y_{s,t},y_{s,r}) - k(y'_{s,t},y'_{s,r}) \big) \Big]\]where \((y_{s,t},y_{s,r})\) and \((y'_{s,t},y'_{s,r})\) are produced from two particles in the same group that share the same sampled \((s,t)\).
Interpretation (why this is “moment matching”):
- MMD matches expectations of all RKHS features induced by $k$, i.e., “many moments at once”.
- The structure above contains within-set terms (encouraging a realistic spread under each route) and cross terms (aligning the two routes), which empirically mitigates the collapse that pointwise regression objectives often suffer from.
In other words, IMM replaces pointwise self-consistency (Shortcut) with distributional self-consistency, while still keeping the same practical recipe: bootstrapping + stop-gradient/EMA + multi-step reuse at inference.
7.4 Practical Design: Choosing r(s,t), Kernel k, and Weights w(s,t)
IMM is conceptually simple, but its empirical success relies on a few practical choices.
(1) Where to place the inductive pivot $r=r(s,t)$. IMM chooses $r$ so that $r$ stays between $(s,t)$ but is not too close to either endpoint, and often uses a schedule based on a monotone “noise-level” variable (e.g., $\eta_t=\sigma_t/\alpha_t$). Intuitively, $r$ defines the “teacher hop length”: too small makes the constraint weak; too large makes targets unreliable early in training.
(2) Kernel choice $k(\cdot,\cdot)$. IMM uses a positive definite kernel (e.g., a Laplace/RBF-like kernel, sometimes with mild time dependence) to robustly compare two sample sets in high dimension:
\[k(a,b)=\exp\Big(-c(s,t)\cdot \|a-b\| \Big),\]with a carefully chosen scaling $c(s,t)$ so that distances at different noise levels remain comparable.
(3) Weighting $w(s,t)$. Not all time pairs are equally important. IMM uses a weight $w(s,t)$ (often expressed via log-SNR $\lambda_t$ or related schedules) to emphasize the time regions that matter most for generation quality and stability.
These choices mirror a recurring theme across fast-generation methods: once we stop doing fine-grained integration, time scheduling becomes part of the model design, not merely a solver detail.
7.5 Sampling: Pushforward Composition and Inference-Time Scaling
After training, IMM supports arbitrary step counts by simply composing the learned operators. Given a schedule
\[0=t_0 < t_1 < \cdots < t_N = 1,\]start from $x_{t_0}\sim p_{\text{init}}$ and iteratively apply
\[x_{t_{i+1}} \leftarrow f_\theta(x_{t_i};\, t_{i+1}, t_i).\]This yields:
- 1-step: $x_1 = f_\theta(x_0;\,1,0)$.
- few-step: $N\in{2,4,8}$ provides intermediate refinements.
- more steps: progressively improves fidelity, analogous to using a finer solver—except here refinement comes from operator composition rather than ODE integration.
From the unified viewpoint of this blog:
- Shortcut learns a step-conditioned displacement $s_\theta(x_t,t,d)$ and composes Euler-style updates.
- MeanFlow learns a mean velocity $u_\theta(x_t,t,t_{\text{end}})$ to realize a large jump consistent with continuous-time theory.
- IMM learns a two-time flow map $f_\theta(\cdot;s,t)$ and enforces the semigroup principle in distribution via moment matching.
In this sense, IMM sits naturally in the “flow map family”: it is an explicit attempt to learn $\Phi_{t\to s}$ without ever committing to fine-grained integration at inference time, and it provides a principled (and empirically stable) alternative to purely pointwise consistency training.
8. References
Lipman Y, Chen R T Q, Ben-Hamu H, et al. Flow matching for generative modeling[J]. arXiv preprint arXiv:2210.02747, 2022. ↩
Lee S, Lin Z, Fanti G. Improving the training of rectified flows[J]. Advances in neural information processing systems, 2024, 37: 63082-63109. ↩
Liu X, Zhang X, Ma J, et al. Instaflow: One step is enough for high-quality diffusion-based text-to-image generation[C]//The Twelfth International Conference on Learning Representations. 2023. ↩
Geng Z, Deng M, Bai X, et al. Mean flows for one-step generative modeling[J]. arXiv preprint arXiv:2505.13447, 2025. ↩
Zhou L, Ermon S, Song J. Inductive Moment Matching[C]//Proceedings of the 42nd International Conference on Machine Learning (ICML). PMLR 267, 2025. ↩ ↩2