
The Consistency Family: From Discrete-Time Constraints to Continuous-Time Flows
Published:
Diffusion models (DMs) and score-based generative models (SGMs) have demonstrated remarkable generative capability, but their iterative sampling procedures require hundreds of function evaluations to approximate the underlying ODE or SDE trajectories accurately. Thus, recent research aims to accelerate generation by distilling multi-step samplers into compact one-step or few-step models.
Consistency Models (CMs) were proposed as a principled framework to enable one-step generation while retaining the expressive power of diffusion processes. The central idea is to directly learn a consistent mapping across the continuous trajectory of the diffusion ODE, such that predictions made at any two time steps $ t $ and $ s $ remain consistent with the same underlying data point $ x_0 $.
1. Preliminaries
1.1 Problem Definition
Define the forward Gaussian probability path (forward diffusion process).
\[x_t = s(t)x_0 + \sigma(t)\epsilon, \quad \epsilon \sim \mathcal{N}(0, I), \quad x_0 \sim p_{\text{data}}(x).\]Recall that in the first article, we introduced that its corresponding continuous PF-ODE is
\[\frac{dx_t}{dt} = v(x_t, t) = \left( \frac{s'(t)}{s(t)}x_t - \sigma(t)^2( \frac{\sigma^'(t)}{\sigma(t)} - \frac{s^'(t)}{s(t)})\nabla_{x_t} \log p_t(x_t) \right)\]This ODE satisfies the continuity equation, ensuring that the trajectory \(\{x_t\}_{t\in [0,1]}\) obtained along this ODE preserves the same time-dependent marginal densities as the stochastic perturbation process.
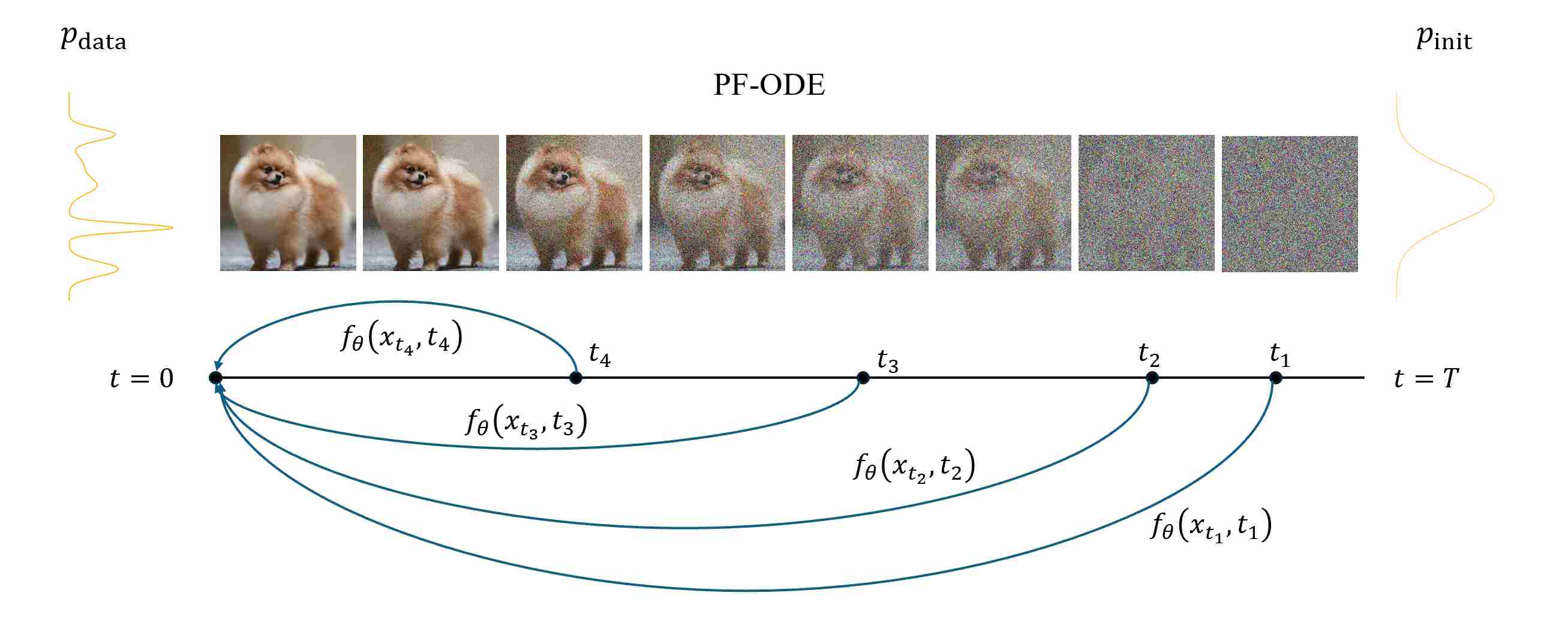
Let $\Phi_{t\to s}$ denote the exact PF-ODE flow that maps a state at time $t$ to time $s\le t$.
\[\Phi_{t\to s}(x_t) \,=\, x_s \,\quad\, \forall\; 0\le s\le t\le T.\]A consistency function \(f_\theta(x_t, t)\) is defined such that it is invariant along the ODE trajectory:
\[f_\theta(x_t, t) = f_\theta(x_s, s), \quad \forall, s < t,\]where \(x_s=\Phi_{t\to s}(x_t)\). $f_\theta$ satisfies the boundary condition
\[f_\theta(x_0, 0) \;\approx\;\Phi_{t\to 0}(x_t) \,=\, x_0.\]This consistency condition implies that $ f_\theta $ remains constant along the trajectory of any valid ODE solution, effectively representing the same clean data point regardless of the diffusion time.
Intuitively, $ f_\theta(x_t, t) $ should project any noisy sample $ x_t $ back to its corresponding clean example $ x_0 $, while maintaining mutual consistency between predictions across all time steps.
1.2 From Definition to Training Paradigms
Although the definition of a consistency function $f_\theta(x_t, t)$ is conceptually elegant—requiring invariance along the diffusion ODE trajectory— it is non-trivial to enforce directly in practice.
In real data, we only observe noisy samples $ x_t $ drawn from the marginal distribution $ p_t(x) $, without access to the exact trajectory or the corresponding clean target $ x_0 $. Therefore, we must design tractable training objectives that approximate this ideal invariance property. Two complementary approaches naturally emerge:
Consistency Distillation (CD): If a teacher generative model (e.g., a pretrained diffusion model or an ODE solver) is available, it can serve as a proxy for the true trajectory. The student consistency model learns to reproduce the teacher’s behavior by enforcing that its prediction at time $ t $ remains consistent with the teacher’s prediction at a previous time $ s<t $.
This yields a teacher-supervised learning paradigm that leverages the high-fidelity trajectory of the pretrained diffusion model.
Consistency Training (CT): When no teacher model is available, consistency can still be enforced self-supervisedly. The model ensures that its own predictions at two nearby timesteps are consistent with each other, effectively learning to preserve invariance along the diffusion path.
This strategy removes external supervision but introduces greater challenges in stability and convergence.
Hence, the two paradigms differ primarily in whether the supervision comes from a teacher model (CD) or from the model’s own temporal consistency (CT). Both share the same theoretical goal: to make $ f_\theta(x_t, t) $ constant along the ODE trajectory, thereby enabling direct one-step generation without explicit integration. The training objective is defined at two adjacent time steps with finite distance:
\[\mathcal{L}_{\text{CM}} = \mathbb{E}_{x_0, \epsilon, n} \Big[w(t)\| f_\theta(x_{t}, t) - f_{\theta}(x_{t-\Delta t}, t-\Delta t) \|_2^2\Big]\]where $w(t)$ is the weighting function, \(\Delta t > 0\) is the distance between adjacent time steps, and \(d(\cdot, \cdot)\) is a metric function which is used to measure the similarity between two high-dimensional vectors, common choices of $d$ including but not limited to: $L_2$ Loss, Pseudo-Huber Loss, and LPIPS Loss. In our following discussion, we will use $L_2$ Loss for analysis.
2. Consistency Distillation
The Consistency Distillation (CD) paradigm assumes the existence of a pretrained teacher model $ g_\phi(x_t, t) $, such as a diffusion model or a deterministic sampler derived from it. The teacher provides a reliable target trajectory for supervision.
Given two time steps $t_n$ and $t_{n-1}=t_n-\Delta t$, the teacher integrates one ODE step to approximate the previous state:
\[\hat{x}_{t_{n-1}} = \Phi_{t_n \to t_{n-1}}(x_{t_n}; g_\phi),\]The student consistency model $ f_\theta $ is then trained to match this target:
\[\mathcal{L}_{\text{CD}} = \mathbb{E}_{x_0, t, \epsilon} \Big[w(t) \, \big\| f_\theta(x_{t_n}, t_n) - f_\theta(\hat{x}_{t_{n-1}}, t_{n-1}) \big\|_2^2\Big]\label{eq:cd},\]2.1 Training Pipeline of CD
The consistency-distillation pipeline can be summarized into the following steps:
Step 1: Sample $x_0$ from the dataset and create a noisy $x_{t_n}$ from forward diffusion process
\[x_t = s(t)\,x_0 + \sigma(t)\,\epsilon,\qquad \epsilon \in \mathcal N(0,I)\]Step 2: Use the pretrained diffusion model $s_{\theta}$ to integrate one ODE step to obtain adjacent position.
\[\hat{x}_{t_{n-1}} = \Phi_{t_n \to t_{n-1}}(x_{t_n}; g_\phi)\]For example, if we have an EDM-Style pre-trained teacher model with $s(t)=1$ and $\sigma(t)=t$, then the PF-ODE is defined by:
\[dx_t = -t\,s_{\theta}(x_t, t)\,dt\]Then, the adjacent position can be approximated by Euler one step.
\[\hat{x}_{t_{n-1}} \,\approx\, x_{t_{n}} + (t_{n} - t_{n-1})t_n\,s_{\theta}(x_{t_n}, {t_n})\label{eq:next}\]We now have a pair sample $(x_{t_n}, \hat{x}{t{n-1}})$ that lies on the same path.
Step 3: Train the objective function (Eq. \ref{eq:cd}) using the collected sample pairs, and solve for the optimal model parameters with optimization algorithms such as gradient descent. In practice, the adjacent point $(x_{t_{n-1}}, t_{n-1})$ is estimated by an EMA network for stability.
\[\mathcal L_{\text{CD}} = \mathbb{E}_{x_0, t, \epsilon} \Big[w(t) \, \big\| f_\theta(x_t, t) - f_{\theta^-}(\hat{x}_{t_{n-1}}, t_{n-1}) \big\|_2^2\Big]\]where $f_\theta$ and $f_{\theta^-}$ are referred to as the student network and the teacher netfork. $ f_{\theta^-} $ is often implemented as an exponential moving average (EMA) of the student network $f_\theta$:
\[\theta^- \leftarrow \text{stopgrad} (\mu {\theta^-} + (1-\mu){\theta})\]
2.2 Why Use an EMA Teacher
Using an EMA teacher provides two key benefits:
Temporal Stability. The EMA weights represent a temporally smoothed version of the student, filtering out high-frequency oscillations and noise introduced by stochastic gradient updates. This produces more coherent and reliable teacher predictions across training iterations, which is crucial for maintaining a stable distillation target.
Implicit Self-Distillation. By updating the teacher gradually, the student always learns from a slightly older but more stable version of itself. This creates a form of self-distillation loop that continuously refines the model’s temporal consistency, improving convergence and reducing overfitting to noisy instantaneous updates.
3. Consistency Training From Scratch
While Consistency Distillation (CD) leverages a high-fidelity teacher model to provide supervision, such a teacher may not always be available, especially when one aims to train a generative model from scratch.
To address this, Consistency Training (CT) introduces a self-supervised alternative that enforces the same principle of temporal invariance without external guidance.
3.1 Unbiased Estimation of Score Model
Recall that in consistency distillation, we rely on a pretrained score model $g_{\phi}$ to approximate the ground truth score function. It turns out that we can avoid this pre-trained score model altogether by leveraging the following unbiased estimator. The key idea is that we use the conditional score, rather than the marginal score, as an estimate of the true score.
We do not know the true marginal probability density $p_t(x_t)$, so we cannot obtain the score directly. However, for a given $x_0$, under the general Gaussian perturbation
\[x_t = s(t)x_0 + \sigma(t)\epsilon ,\qquad x_0\sim p_{\text{data}},;\epsilon\sim\mathcal N(0,I),\]the conditional probability density $p_t(x_t \mid x_0)$ follows a Gaussian distribution
\[p_t(x_t \mid x_0) = \mathcal N(s(t)x_0,\, \sigma(t)^2\,I)\]and the marginal at time $t$ is the mixture (convolution) of that kernel with the data distribution:
\[p_t(x_t) = \int_{x_0} p_t(x_t\mid x_0) p_{\text{data}}(x_0) dx_0\]Take the derivative of both sides with respect to $x_t$, using Bayes’ rule
\[\begin{align} \nabla_{x_t} p_t(x_t) & = \int_{x_0} \nabla_{x_t} p_t(x_t\mid x_0) \cdot p_{\text{data}}(x_0) dx_0 \\[10pt] \Longrightarrow\, p_t(x_t)\cdot \nabla_{x_t} \log p_t(x_t) & = \int_{x_0} \nabla_{x_t} \log p_t(x_t\mid x_0)\cdot p_t(x_t\mid x_0)\cdot p_{\text{data}}(x_0) dx_0 \\[10pt] \Longrightarrow\, \nabla_{x_t} \log p_t(x_t) & = \int_{x_0} \nabla_{x_t} \log p_t(x_t\mid x_0)\cdot \frac{ p_t(x_t\mid x_0)\cdot p_{\text{data}}(x_0)}{p_t(x_t)} dx_0 \\[10pt] \Longrightarrow\, \nabla_{x_t} \log p_t(x_t) & = \int_{x_0} \nabla_{x_t} \log p_t(x_t\mid x_0)\cdot p_t(x_0 \mid x_t) dx_0 \\[10pt] \Longrightarrow\, \nabla_{x_t} \log p_t(x_t) & = \mathbb E(\nabla_{x_t} \log p_t(x_t\mid x_0) \mid x_t) \end{align}\]Taking the conditional expectation then gives the unbiased score estimator used by CT:
\[\nabla_{x_t} \log p_t(x_t) = \mathbb E(\nabla_{x_t} \log p_t(x_t\mid x_0) \mid x_t) = - \mathbb E(\frac{x_t - s(t)x_0}{\sigma(t)^2} \mid x_t)\label{eq:ct_unbias}\]Specifically, we consider EDM-Style diffusion model with $s(t)=1$ and $\sigma(t)=t$ yields
\[\nabla_{x_t} \log p_t(x_t) = - \mathbb E(\frac{x_t - x_0}{t^2} \mid x_t)\label{eq:ct_unbias2}\]3.2 From CD to CT via Unbiased Substitution
Since we have obtained an unbiased estimate of the score, substituting \ref{eq:ct_unbias2} into Eq. \ref{eq:next} to get the estimate of the next point.
\[\begin{align} \hat{x}_{t_{n-1}} & = x_{t_n} + (t_n-t_{n-1})t_n \log p_t(x_{t_n}) \\[10pt] & = x_{t_n} - (t_n-t_{n-1}) \frac{x_{t_n}-x_0}{t_n} \\[10pt] & = x_0 + t_{n-1} \epsilon \end{align}\]Intuitively, CT approximates $x_{t_{n-1}}=x_{t−∆t}$ in discrete-time CMs by reusing the same data $x_0$ and noise $\epsilon$ when sampling $x_{t_n}$. The objective function now can be rewritten as
\[\mathcal{L}_{\text{CT}} = \mathbb{E}_{x_0, t, \epsilon} \Big[w(t) \, \big\| f_\theta(x_0+t_n \epsilon, t_n) - f_\theta(x_0 + t_{n-1} \epsilon , t_{n-1}) \big\|_2^2\Big]\]3.3 The Equivalence of CD and CT
Let $ \Delta t = \max_n |t_{n+1} - t_n| $. Assume that the distance function (d(\cdot,\cdot)) and the target network $f_{\theta^-}$ are twice continuously differentiable with bounded second derivatives, the weighting function $w(t)$ is bounded, and that the expected squared norm of the score \(\mathbb{E}\|\nabla \log p_t(x_t)\|_2^2\) is finite. If the pre-trained score model matches the ground-truth score $s_\phi(x,t) = \nabla_x \log p_t(x)$ and the Euler ODE solver is used, then the following holds:
\[L^{(N)}_{\mathrm{CD}}(\theta, \theta^-; \phi)= L^{(N)}_{\mathrm{CT}}(\theta, \theta^-)+ O(\Delta t).\]Hence, in the limit $\Delta t \to 0$ and $ N \to \infty $, optimizing the Consistency Distillation loss is equivalent to optimizing the Consistency Training loss.
The proof is established through a first-order Taylor expansion of the target term in the CD loss and the unbiased score identity derived from the Gaussian corruption process.
Step 1: Taylor expansion of teacher network. For a given sample $x_{t_{n}}$ and timestep $t_{n}$, CD uses the Euler solver to generate the teacher prediction:
\[\hat{x}_{t_{n-1}} = x_{t_{n}} + (t_{n} - t_{n-1})\,t_n\,s_\theta(x_{t_n},t_n)\]Let \(v_{\theta}(x_{t_n},t_n)=-t_n\,s_\theta(x_{t_n},t_n)\), expanding the target network around $(x_{t_{n}}, t_{n})$ by first-order Taylor expansion
\[\small \begin{align} f_{\theta^-}(\hat{x}_{t_{n-1}}, t_{n-1}) & = f_{\theta^-}(x_{t_{n}}, t_{n}) + \big[ \partial_x f_{\theta^-}(x_{t_{n}}, t_{n})(\hat{x}_{t_{n-1}}-x_{t_n}) + \partial_t f_{\theta^-}(x_{t_{n}}, t_{n})(t_{n-1}-t_n) \big] + O(\Delta t) \\[10pt] & = f_{\theta^-}(x_{t_{n}}, t_{n}) - \Delta t \big[ \partial_x f_{\theta^-}(x_{t_{n}}, t_{n}) v_{\theta}(x_{t_n}, t_n) + \partial_t f_{\theta^-}(x_{t_{n}}, t_{n}) \big] + O(\Delta t) \end{align}\]For CT, we substitute the unbiased score identity induced by the Gaussian corruption kernel:
\[\small \begin{align} & f_{\theta^-}(x_{t_{n}}, t_{n}) - \Delta t \big[ \partial_x f_{\theta^-}(x_{t_{n}}, t_{n}) v_{\theta}(x_{t_n}, t_n) + \partial_t f_{\theta^-}(x_{t_{n}}, t_{n})\big] + O(\Delta t) \\[10pt] = & f_{\theta^-}(x_{t_{n}}, t_{n}) - \Delta t \big[ \partial_x f_{\theta^-}(x_{t_{n}}, t_{n})t_n\,\frac{x_{t_n}-x_0}{t_n^2} + \partial_t f_{\theta^-}(x_{t_{n}}, t_{n})\big] + O(\Delta t) \\[10pt] = & f_{\theta^-}(x_{t_{n}}, t_{n}) + \big[ \partial_x f_{\theta^-}(x_{t_{n}}, t_{n})(- \Delta t)\frac{x_{t_n}-x_0}{t_n} + \partial_t f_{\theta^-}(x_{t_{n}}, t_{n})(- \Delta t)\big] + O(\Delta t) \\[10pt] = & f_{\theta^-}(x_{t_{n}}+(- \Delta t)\frac{x_{t_n}-x_0}{t_n} , t_n + (- \Delta t)) \\[10pt] = & f_{\theta^-}(x_0+t_{n-1}\frac{x_{t_n}-x_0}{t_n} , t_{n-1}) \end{align}\]It means that when we use an unbiased estimator to replace the true score, the Taylor expansion of the teacher network around $(t_n, x_{t_n})$ is first-order equivalent.
Step 2: Taylor expansion of the Loss function. take taylor expansion of the metric $d$ in its second argument
\[\mathbb E(d(x, y+\Delta)) = \mathbb E(d(x, y)) + \mathbb E(\partial_2 d(x, y)\cdot \Delta) + o(\Delta)\]where \(\partial_2\) means the gradient of the function $d$ with respect to its second argument. This equality holds for any metric function. Consider the loss function of CD.
\[\mathcal L_{\text{CD}} = \mathbb E(d(x, y+\Delta)) = \mathbb E(d(x, y)) + \mathbb E(\partial_2 d(x, y)\cdot \Delta_{\text{CD}}) + o(\Delta)\]where
\[\begin{align} & x = f_{\theta}(x_{t_n}, t_n), \quad y = f_{\theta^-}(x_{t_{n-1}}, t_{n-1}) \\[10pt] & \Delta_{\text{CD}} = (- \Delta t) \big[ \partial_x f_{\theta^-}(x_{t_{n}}, t_{n}) v_{\theta}(x_{t_n}, t_n) + \partial_t f_{\theta^-}(x_{t_{n}}, t_{n})\big] + O(\Delta t) \end{align}\]When it comes to the loss function of CT,
\[\mathcal L_{\text{CT}} = \mathbb E(d(x, y+\Delta)) = \mathbb E(d(x, y)) + \mathbb E(\partial_2 d(x, y)\cdot \Delta_{\text{CT}}) + o(\Delta)\]where
\[\begin{align} & x = f_{\theta}(x_{t_n}, t_n), \quad y = f_{\theta^-}(x_{t_{n-1}}, t_{n-1}) \\[10pt] & \Delta_{\text{CT}} = (- \Delta t) \big[ \partial_x f_{\theta^-}(x_{t_{n}}, t_{n})\frac{x_{t_n}-x_0}{t_n} + \partial_t f_{\theta^-}(x_{t_{n}}, t_{n})\big] + O(\Delta t) \end{align}\]The difference between the $\mathcal L_{\text{CT}}$ and $\mathcal L_{\text{CD}}$ lies in $\Delta$, we have already proven in the step 1 that replacing with an unbiased estimator makes this two first-order equivalent, therefore
\[\mathcal L_{\text{CD}} = \mathcal L_{\text{CT}} + o(\Delta t)\]
4. From Discrete to Continuous Consistency Models
Despite the empirical success of discrete-time consistency models (CMs) in enabling few-step or even one-step sampling, their formulation inherits several intrinsic limitations stemming from the discretization of the underlying probability-flow ODE. These limitations not only restrict theoretical understanding but also hinder scalability and stability when training at high resolutions or with complex noise schedules. The transition to a continuous-time formulation is therefore not merely an aesthetic reformulation but a principled extension that resolves fundamental weaknesses in the discrete regime.
Discretization Error and Supervision Bias. Discrete CMs rely on numerical solvers to approximate the transition between two adjacent timesteps, typically using Euler or Runge–Kutta integration. The teacher’s prediction at the earlier step, $\hat{x}_{t-\Delta t}$, is thus an approximation rather than an exact ODE state. This introduces a discretization bias into the training target, which propagates through the loss function.
When the step size $\Delta t$ is large, this bias becomes significant, and the supervision signal deviates from the true PF-ODE trajectory, deteriorating sample quality.
Sensitivity to Step-Size Scheduling. The discrete formulation requires a predefined set of timesteps ${t_n}_{n=1}^N$ and an associated weighting schedule $w(t_n)$. Both the choice of step size $\Delta t$ and the weighting function strongly affect convergence and visual fidelity, often necessitating extensive empirical tuning. Moreover, using excessively small steps leads to unstable gradients, while large steps amplify bias.
4.1 From Discrete to Continuous Objective
To overcome the aforementioned discretization bias and parameter sensitivity, we reformulate the discrete-time objective into a continuous-time consistency objective. This transition is grounded in a rigorous limiting process that connects the finite-step consistency loss to its infinitesimal counterpart. Recall the discrete objective defined between two adjacent timesteps:
\[\mathcal{L}_{\text{disc}} = \mathbb{E}_{x_0, t, \epsilon}\Big[w(t)\,\| f_\theta(x_t, t) - f_{\theta^-}(x_{t-\Delta t}, t-\Delta t)\|_2^2\Big].\]Here, $\Delta t > 0$ denotes the step size between consecutive timesteps along the probability-flow ODE trajectory. In practice, $x_{t-\Delta t}$ is obtained by numerically integrating the PF-ODE backward by $\Delta t$, introducing a discretization error of order $O(\Delta t^2)$ (Euler).
We expand the teacher’s prediction around the current point $(x_t, t)$ along the PF-ODE direction:
\[\small \begin{align} f_{\theta^-}(x_{t-\Delta t}, t-\Delta t) & = f_{\theta^-}(x_t, t) -\Delta t\Big(\nabla_x f_{\theta^-}(x_t, t),\frac{dx_t}{dt} + \partial_t f_{\theta^-}(x_t, t)\Big) + O(\Delta t^2) \\[10pt] & = f_{\theta^-}(x_t, t) -\Delta t,\frac{d}{dt}f_{\theta^-}(x_t, t) + O(\Delta t^2)\label{eq:tmp} \end{align}\]where the total derivative
\[\frac{d}{dt}f_{\theta^-}(x_t,t) =\partial_x f_{\theta^-}(x_t,t)\,\frac{dx_t}{dt}+\partial_t f_{\theta^-}(x_t,t)\]represents the tangent of $f_{\theta^-}$ along the PF-ODE trajectory. Substitute Eq. \ref{eq:tmp} into the discrete objective gives
\[\mathcal{L}_{\text{disc}}=\mathbb{E}\Big[w(t)\,\big\| \underbrace{f_\theta(x_t,t) - f_{\theta^-}(x_t,t)}_{\nabla f_t} + \Delta t\,\frac{d}{dt}f_{\theta^-}(x_t,t)\big\|_2^2\Big] + O(\Delta t^2)\label{eq:disc}\]Differentiating Eq. \ref{eq:disc} with respect to $\theta$ (noting $\theta^-$ is stop-grad), we obtain
\[\nabla_\theta \mathcal{L}_{\text{disc}}=2\,\mathbb{E}\!\Big[w(t)\,(\nabla_\theta f_\theta(x_t, t))^{\!\top} (\Delta f_t+\Delta t\,\frac{d}{dt}f_{\theta^-}(x_t,t))\Big]\]In the infinitesimal limit $\Delta t \to 0$, the discrepancy $\Delta f_t$ vanishes since $f_\theta$ and $f_{\theta^-}$ represent nearly identical predictions at the same point. Retaining only first-order terms yields the continuous-time gradient form:
\[\nabla_\theta \mathcal{L}_{\text{cont}}=\frac{\nabla_\theta \mathcal{L}_{\text{cont}}}{\Delta t} = \nabla_\theta\,\mathbb{E}\!\left[w(t)\,f_\theta(x_t,t)^{\!\top}\,\frac{d}{dt}f_{\theta^-}(x_t,t)\right]\]